- تله سرمایه گذار: از خفه کردن و سوزاندن مراقب باشید
- 7 راه برای استفاده از هوش مصنوعی اکنون برای تأثیرگذاری بر مدیریت ریسک و جلوگیری از غرق شدن در داده ها
- مبادلات ، سوپر های الکترونیکی و بازپرداخت
- الگوریتم های معاملاتی هوشمند
- گزینه های سرمایه گذاری
- ثروتمندترین معامله گران فارکس
- 4 دلیل شما باید Dogecoin را بفروشید و چرا ممکن است آن را حفظ کنید
- سرمایه گذاری در مایع هوایی
- بحران ارز
- سهام جویدنی به عنوان درآمد نشان می دهد که تعداد مشتری را کاهش می دهد ، پیش بینی رشد سود

آخرین مطالب
امکانات وب


تجزیه و تحلیل تطبیقی از داده های بازار سهام نزدیک با قیمت نزدیک با سری زمانی کلاسیک ، یادگیری ماشین و یک مدل شبکه عصبی تک لایه
پیش بینی داده های یک سری زمانی (بازار سهام) در r
یک مطالعه تطبیقی توسط ،
Shreyashi Saha و Sagail Bose
دانشجویان کارشناسی ارشد در آمار

فهرست
بررسی اجمالی
معرفی
مجموعه داده ها و تجسم های پیشرفته
مواد و روش ها
- ARIMA: ادغام اتورگرایی مدل متوسط در حال حرک ت-نتای ج-ARIMA
- GARCH: مدل هتروسکوپیک مشروط مشروط تعمیم یافت ه-پیش بینی نتای ج-GARCH
- پیش بینی پیامبر و پیش بینی نتایج پیش بینی
- پیش بینی سری رگرسیون K-NN
- شبکه عصبی Feed Foward
نتیجه
ارجاع
بررسی اجمالی
این پروژه مدل های مختلف پیش بینی سری و یادگیری ماشین را توصیف می کند که به یک مجموعه داده نزدیک قیمت سهام واقعی اعمال می شود. برای این پروژه با یک ایده کلی از قیمت سهام ، از جمله تجزیه و تحلیل مجموعه داده ها شروع خواهیم کرد. به دنبال توضیحات و تجزیه و تحلیل کلی از مجموعه داده ، هدف ما استفاده از مدل های پیش بینی پیش بینی مختلف برای سهام نزدیک به سهام "S & P500" است. به دنبال دستورالعمل های اصلی پروژه دوره ، مدل ها ارزیابی ، تجزیه و تحلیل و مقایسه می شوند. داده ها برای پیش بینی قیمت نزدیک 30 روز آینده از امروز آماده خواهند شد. نتایج در طول گزارش به همراه اظهارات نتیجه گیری توضیح داده خواهد شد.
معرفی
یک الگوریتم پیش بینی کننده یک فرایند اطلاعاتی است که می خواهد مقادیر آینده را بر اساس داده های گذشته و حال پیش بینی کند. این نقاط داده های تاریخی در تلاش برای پیش بینی مقادیر آینده برای یک متغیر انتخاب شده از مجموعه داده ها استخراج و آماده می شوند. در این رویکرد پروژه ما بر پیش بینی کمی که شامل متغیر ما برای پیش بینی (قیمت نزدیک) ، تجزیه و تحلیل آماری آن و مفاهیم پیشرفته اعمال شده برای داده های تاریخی خاص باشد ، تمرکز خواهیم کرد.
از نظر تاریخی ، علاقه مداوم به تلاش برای تجزیه و تحلیل تمایلات بازار ، رفتار و واکنش های تصادفی وجود داشته است. این نگرانی مداوم برای درک آنچه اتفاق می افتد قبل از اینکه واقعاً اتفاق می افتد ما را به ادامه این مطالعه انگیزه می دهد. برخی از بازرگانان و اقتصاددانان بزرگ بازار می گویند که پیش بینی بازده سهام یا قیمت های مربوط به آن ، استقلال بین یکدیگر ، از حرکات یا روندهای گذشته برای پیش بینی ارزشهای آینده استفاده نمی شود ، که توسط تئوری پیاده روی تصادفی ، اسکیت ، کورتوز و تصادفی بزرگ توضیح داده نمی شود. جزء. با مدل های جدید پیشرفته جدید ، ما سعی خواهیم کرد که در برابر جریان پیش برویم ، زیرا ، چرا نه؟از آنجا که این یک پروژه علوم داده است ، این مدل های پیش بینی به عنوان Oracles در نظر گرفته نمی شوند ، اما برای تجزیه و تحلیل حرکات قیمت سهام با رویکرد آماری واقعاً مفید هستند. هدف اصلی این تحقیق نشان دادن مدل های متناسب ، مقایسه آنها و تشویق استفاده از آنها است.
ابتدا به ما اجازه دهید کتابخانه های زیر را در محیط R بارگذاری کنیم
کتابخانه #کتابخانه (QuantMod) کتابخانه (GGPLOT2) کتابخانه (پیش بینی) کتابخانه (TSERIES) کتابخانه (Rugarch) کتابخانه (پیامبر) کتابخانه (TSFKNN) اگر کتابخانه ها نصب نشده اند ، بسته های مورد نیاز را با نصب نصب کنید.
مجموعه داده ها و تجسم های پیشرفته
اولا ، ما نگاهی اجمالی به داده ها می اندازیم.
getSymbols ("^gspc" ، src = "https://stat-wizards. github. io/forcasting-a-time-series-stock-market-data/yahoo" ، از = "2015-01-01" ، تا= "2020-06-04") سر (GSPC) 2022. 15 2030. 25 1992. 44 2002. 61 4460110000 2002. 61 # 2015-01-07 2005. 55 2029. 61 2005. 55 2025. 90 3805480000 2025. 90 # 2015-01-08 2030. 61 2064. 08 2030. 61 2061 2061 2062 45 2064. 43 2038. 33 2044. 81 3364140000 2044. 81 اکنون ، ما سعی می کنیم داده های نزدیک قیمت را با نمودار زیر تجسم کنیم
ChartSeries (GSPC ، TA = NULL) 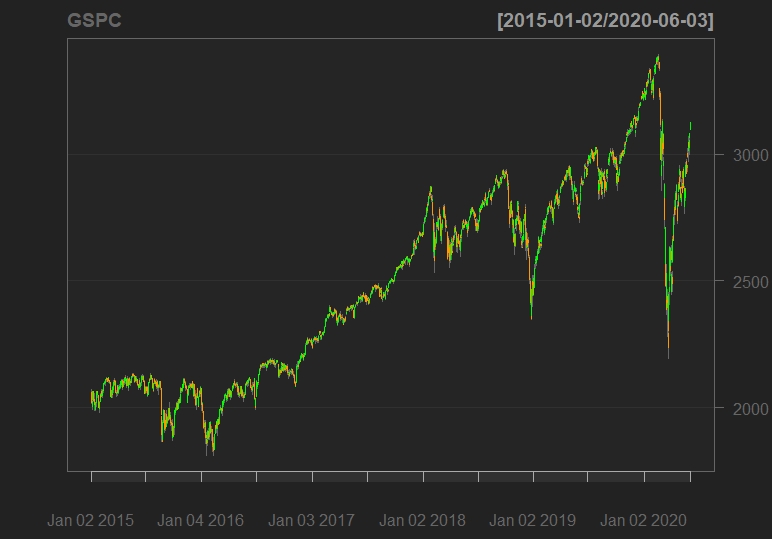
برای نمای پیشرفته تر ، نمودار باند بولینگر ، ٪ تغییر Bollinger ، حجم معامله شده و واگرایی همگرایی متوسط را به نمودار فوق اضافه می کنیم.
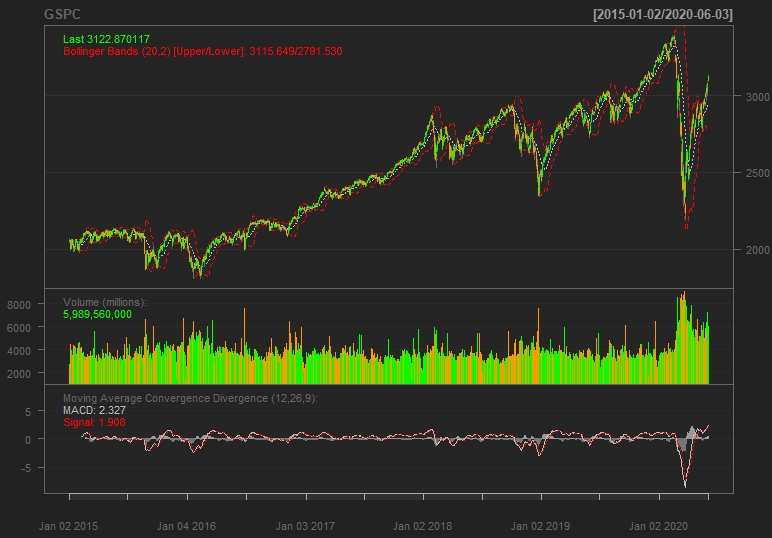
برای یک کد دقیق تر از اینجا بازدید کنید.
اکنون ، برای تجزیه و تحلیل نمودارهای میانگین همگرایی در حال حرکت فوق ، ما به کمی دانش واژگان تجارت و برخی روشهای تجربی درک داده های نزدیک قیمت نیاز داریم. بنابراین MACD چیست؟
میانگین واگرایی همگرایی در حال حرکت (MACD):
جابجایی میانگین همگرایی واگرایی (MACD) یک شاخص حرکت در حال دنبال است که رابطه بین دو میانگین متحرک قیمت یک امنیت را نشان می دهد. MACD با کم کردن میانگین حرکت 26 دوره نمایی (EMA) از EMA 12 دوره محاسبه می شود.
فرمول:
MACD = 12 دوره EMA-26-دوره EMA
اکنون ، ما باعث می شود که شما با ما استفاده کنید و یک اصطلاحات دیگر را با دیگری توضیح دهیم اما لطفاً فقط یک لحظه با ما همراه باشید. بنابراین EMA چیست؟
میانگین متحرک نمایی (EMA) نوعی میانگین متحرک (MA) است که وزن و اهمیت بیشتری را در جدیدترین نقاط داده قرار می دهد. میانگین متحرک نمایی نیز به عنوان میانگین متحرک با وزنی نمایی گفته می شود. میانگین متحرک با وزنی به صورت نمایی نسبت به میانگین متحرک ساده (SMA) نسبت به تغییرات قیمت اخیر واکنش قابل توجهی دارد ، که وزن مساوی را برای تمام مشاهدات در دوره اعمال می کند.
نتیجه آن محاسبه خط MACD است. سپس یک EMA نه روزه MACD به نام "خط سیگنال" در بالای خط MACD ترسیم شده است که می تواند به عنوان محرک خرید و فروش سیگنال ها عمل کند. معامله گران ممکن است امنیت را خریداری کنند وقتی MACD از بالای خط سیگنال خود عبور می کند و امنیت را می فروشد - یا کوتاه - وقتی MACD از زیر خط سیگنال عبور می کند. شاخص های میانگین واگرایی همگرایی (MACD) را می توان از چند طریق تفسیر کرد ، اما روش های متداول تر متقاطع ، واگرایی و افزایش سریع/سقوط است.
پس چرا باید در مورد MACD بدانید؟
- میانگین واگرایی همگرایی در حال حرکت (MACD) با کم کردن میانگین متحرک 26 دوره نمایی (EMA) از EMA 12 دوره محاسبه می شود.
- MACD هنگام عبور از بالا (برای خرید) یا زیر (برای فروش) خط سیگنال خود ، سیگنال های فنی را ایجاد می کند.
- سرعت متقاطع نیز به عنوان سیگنال یک بازار بیش از حد مورد استفاده قرار می گیرد.
- معامله گران از MACD برای شناسایی هنگام حرکت صعودی (↑) یا Bearish (↓) استفاده می کنند تا بتوانند نقاط ورود و خروج از معاملات را شناسایی کنند.
- MACD توسط معامله گران فنی در سهام ، اوراق قرضه ، کالاها و بازارهای FX استفاده می شود
یادگیری از MACD:
MACD هر زمان که EMA 12 دوره ای (آبی) بالاتر از EMA 26 دوره (قرمز) باشد و یک مقدار منفی باشد وقتی EMA 12 دوره زیر EMA 26 دوره است ، ارزش مثبت دارد. هرچه MACD در بالا یا پایین تر از پایه آن فاصله دارد ، نشان می دهد که فاصله بین دو EMA در حال رشد است. MACD اغلب با یک هیستوگرام نمایش داده می شود (نمودار زیر را ببینید) که فاصله بین MACD و خط سیگنال آن را نشان می دهد. اگر MACD بالاتر از خط سیگنال باشد ، هیستوگرام بالاتر از پایه MACD خواهد بود. اگر MACD زیر خط سیگنال خود باشد ، هیستوگرام زیر پایه MACD قرار خواهد گرفت. معامله گران از هیستوگرام MACD استفاده می کنند تا هنگام حرکت صعودی یا نزولی زیاد باشد.
محدودیت ها :
یکی از اصلی ترین مشکلات واگرایی این است که اغلب می تواند یک معکوس احتمالی را نشان دهد اما در واقع هیچ معکوس واقعی رخ نمی دهد - این یک مثبت کاذب ایجاد می کند. مشکل دیگر این است که واگرایی همه معکوس ها را پیش بینی نمی کند. به عبارت دیگر ، معکوس های زیادی را پیش بینی می کند که اتفاق نمی افتد و معکوس قیمت واقعی کافی نیست.
اکنون ، به اندازه کافی از تجارت فنی و درک تجربی از داده ها. بیایید برخی از استاتیک ها را از قبل انجام دهیم.
بدیهی است ، ما با یک کلاسیک شروع می کنیم ، یادگیری ماشین می تواند منتظر بماند؟
مواد و روش ها
ARIMA: یکپارچه سازی خودکار میانگین متحرک
ARIMA مخفف میانگین متحرک یکپارچه خودجوش است. Arima همچنین به عنوان رویکرد باکس-جنکینز شناخته می شود. باکس و جنکینز ادعا کردند که داده های غیر ثابت را می توان با تفاوت در سریال ، y ثابت کردtبشرمدل کلی برای ytنوشته شده است ،
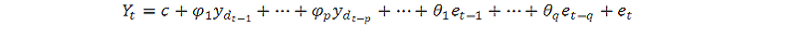
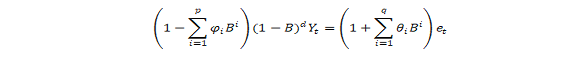
یا،
کجا ، ytمقدار سری زمانی متفاوت است ، ϕ و θ پارامترهای ناشناخته و E اصطلاحات خطای توزیع شده یکسان با میانگین صفر هستند. اینجا ، ytاز نظر مقادیر گذشته خود و مقادیر فعلی و گذشته اصطلاحات خطا بیان شده است.
مدل ARIMA سه روش اساسی را ترکیب می کند:
- رگرسیون خودکار (AR): در رگرسیون خودکار مقادیر داده های سری زمانی معین بر روی مقادیر عقب مانده خود رکود می شوند ، که با مقدار "P" در مدل نشان داده شده است.
- تفاوت (من برای یکپارچه): این شامل متفاوت بودن داده های سری زمانی برای حذف روند و تبدیل یک سری زمانی غیر ثابت به یک ثابت است. این توسط مقدار "D" در مدل نشان داده شده است. اگر d = 1 باشد ، به تفاوت بین دو ورودی سری زمانی نگاه می کند ، اگر d = 2 به تفاوت تفاوت های به دست آمده در d = 1 و غیره نگاه می کند.
- میانگین متحرک (MA): ماهیت MA مدل توسط مقادیر Q نشان داده شده است که تعداد مقادیر عقب مانده اصطلاح خطا است.
این مدل به طور متوسط در حال حرکت یکپارچه یا ARIMA (P ، D ، Q) YT نامیده می شود. ما برای ساخت مدل خود مراحل ذکر شده در زیر را دنبال خواهیم کرد.
مرحله 1: آزمایش و اطمینان از ثابت بودن
برای مدل سازی یک سری زمانی با رویکرد باکس-جنکینز ، این سریال باید ثابت باشد. یک سری زمانی ثابت به معنای یک سری زمانی بدون روند است ، یکی از میانگین و واریانس ثابت در طول زمان ، که این امر پیش بینی مقادیر را آسان می کند.
آزمایش برای ثابت بودن-ما با استفاده از تست ریشه واحد Dickey-Fuller تقویت شده ، برای ثابت بودن آزمایش می کنیم. مقدار P ناشی از آزمون ADF برای یک سری زمانی باید کمتر از 0. 05 یا 5 ٪ باشد. اگر مقدار p از 0. 05 یا 5 ٪ بیشتر باشد ، نتیجه می گیرید که سری زمانی دارای ریشه واحد است و این بدان معنی است که این یک فرآیند غیر ثابت است.
تفاوت-برای تبدیل یک فرآیند غیر ثابت به یک فرآیند ثابت ، ما از روش متفاوت استفاده می کنیم. متفاوت بودن یک سری زمانی به معنای یافتن تفاوت بین مقادیر متوالی داده های سری زمانی است. مقادیر مختلف یک مجموعه داده سری جدید را تشکیل می دهند که می تواند برای کشف همبستگی های جدید یا سایر خصوصیات آماری جالب آزمایش شود.
ما می توانیم بیش از یک بار روش متفاوت را به طور متوالی اعمال کنیم ، و به "تفاوت های اول" ، "اختلاف نظم دوم" و غیره منجر می شود. ما سفارش متفاوت (D) را اعمال می کنیم تا یک سری زمانی ثابت کنیم قبل از اینکه بتوانیم به مرحله بعدی برسیمگام.
مرحله 2: شناسایی P و Q
در این مرحله ، ما با استفاده از عملکرد همبستگی (ACF) و عملکرد همبستگی جزئی (PACF) ، ترتیب مناسب فرآیندهای اتورگرایی (AR) و میانگین حرکت (MA) را شناسایی می کنیم.
با شناسایی ترتیب P مدل AR برای مدل های AR ، ACF به صورت نمایی کاهش می یابد و از PACF برای شناسایی ترتیب (P) مدل AR استفاده می شود. اگر ما یک سنبله قابل توجه در LAG 1 در PACF داشته باشیم ، ما یک مدل AR از سفارش 1 ، یعنی AR (1) داریم. اگر در LAG 1 ، 2 و 3 در PACF سنبله های قابل توجهی داشته باشیم ، یک مدل AR از سفارش 3 ، یعنی AR (3) داریم.
با شناسایی ترتیب Q مدل MA برای مدل های MA ، PACF به صورت نمایی کاهش می یابد و از طرح ACF برای شناسایی ترتیب فرآیند MA استفاده می شود. اگر ما یک سنبله قابل توجه در LAG 1 در ACF داشته باشیم ، ما یک مدل MA از سفارش 1 ، یعنی Ma (1) داریم. اگر در LAG 1 ، 2 و 3 در ACF سنبله های قابل توجهی داشته باشیم ، ما یک مدل MA از سفارش 3 ، یعنی Ma (3) داریم.
مرحله 3: تخمین و پیش بینی
پس از تعیین پارامترها (P ، D ، Q) ، دقت مدل ARIMA را در یک مجموعه داده آموزشی تخمین می زنیم و سپس از مدل متناسب برای پیش بینی مقادیر مجموعه داده های آزمون با استفاده از یک عملکرد پیش بینی استفاده می کنیم. در پایان ، ما بررسی می کنیم که آیا مقادیر پیش بینی شده ما مطابق با مقادیر واقعی است یا خیر.
ابتدا یک آزمایش ADF را برای مجموعه قیمت نزدیک انجام می دهیم:
## چاپ آزمون ADF (adf. test (GSPC $ gspc. close)) # آزمون افزودنی DICKEY-FULLER # DATA: GSPC $ GSPC. CLOSE # DICKEY-FULLER = -4. 2322 ، ترتیب تاخیر = 11 ، P-Value = 0. 01 # فرضیه جایگزین: ثابت پس از آزمایش ADF ما توابع ACF (عملکرد همبستگی) و PACF (عملکرد همبستگی جزئی) را به مجموعه داده اعمال می کنیم.
## plot acf و pacf par (mfrow = c (1 ، 2)) acf (gspc $ gspc. close) pacf (gspc $ gspc. close) par (mfrow = c (1 ، 1)) #dev. off () 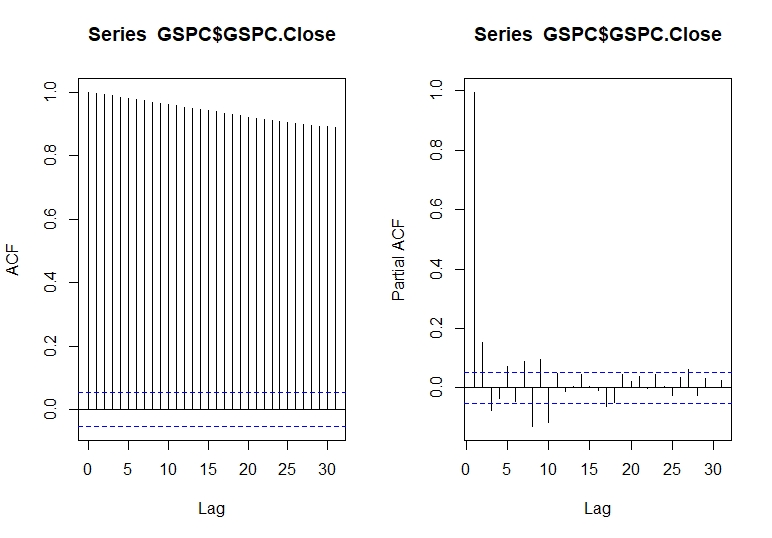
همبستگی به چگونگی ارتباط یک سری زمانی با مقادیر گذشته اشاره دارد. همانطور که در مدل های AR می دانیم ACF به صورت نمایی کاهش می یابد. ACF نقشه ای است که برای دیدن همبستگی بین نقاط ، تا و از جمله واحدهای تاخیر استفاده می شود. ما می توانیم ببینیم که همبستگی برای تعداد زیادی تاخیر قابل توجه است ، اما شاید همبستگی در تاخیر خلفی صرفاً به دلیل انتشار همبستگی در اولین تاخیر باشد.
ما از طرح ACF و PACF برای شناسایی ترتیب (q) استفاده می کنیم و PACF به صورت نمایی کاهش می یابد. اگر می توانیم توجه داشته باشیم که این یک سنبله قابل توجه است که فقط در ابتدا تاخیر وجود دارد ، به این معنی که تمام همبستگی مرتبه بالاتر به طور مؤثر توسط اولین همبستگی تاخیر توضیح داده می شود.
اکنون ، ما مدل خود را با داده های قیمت قرار می دهیم.
## استفاده از auto. arima () در مجموعه داده ها اکنون می توانیم عوامل مدل خود را ببینیم.
# سری: GSPC $ GSPC. CLOSE # ARIMA (5،1،2) # Box Cox Transformation: Lambda = -0. 7182431 # ضرایب: # AR1 AR2 AR3 AR4 AR5 MA2 # -1. 650 3-0. 8038 0. 0364 0. 0502 0. 0502 0. 0502 0. 0502 0. 0502 0. 0502 0. 0502 0. 0502 0. 0502 0. 0502 0. 0502 0. 0502 0. 0502 0. 0502 0. 0502 0. 0502. 0. 0863 0: F1 #مجموعه آموزش 1. 211636 31. 65724 17. 56103 0. 04474109 0. 7083487 1. 01603 7-0. 02548426 با خلاصه مدل ما می توانیم باقیمانده مدل را با پارامترهای ARIMA انتخاب کنیم
# تشخیص در طرح باقیمانده (باقیمانده (modelfit) ، ylab = "باقیمانده" ، اصلی = "باقیمانده (ARIMA (5،1،2)) در مقابل زمان") 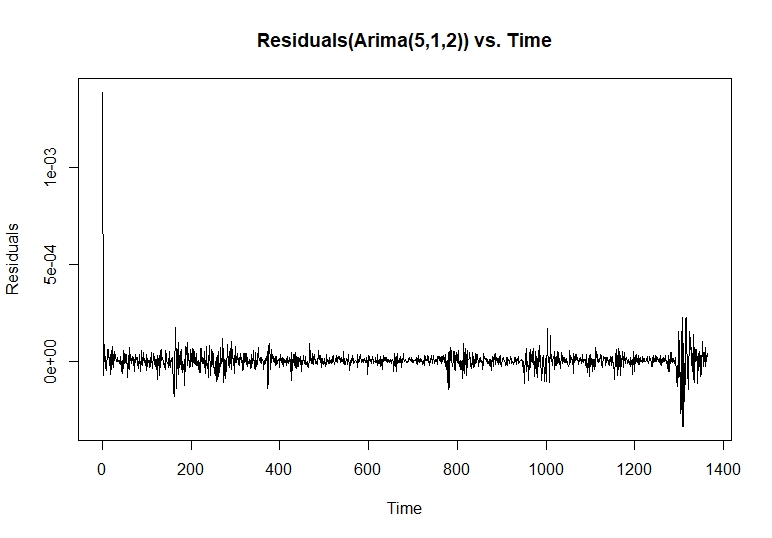
"باقیمانده" در یک مدل سری زمانی همان چیزی است که پس از قرار دادن یک مدل باقی مانده است. در اکثر مدل های سری زمانی ، باقیمانده ها با تفاوت بین مشاهدات و مقادیر مناسب برابر هستند:
همانطور که ما برخی از تست های همبستگی را با مجموعه داده خود انجام دادیم ، اکنون باقیمانده های خود را بر روی یک منحنی عادی بررسی می کنیم.
# هیستوگرام باقیمانده ها و عادی بودن فرضیه HIST (MODELFIT) ، FREQ = F ، YLIM = C (0،9500) ، اصلی = "هیستوگرام باقیمانده") E = منحنی باقیمانده (Modelfit) (DNORM (x ، میانگین = میانگین = میانگین = میانگین = میانگین = میانگین =(e) ، sd = sd (e)) ، add = true ، col = "darkred") 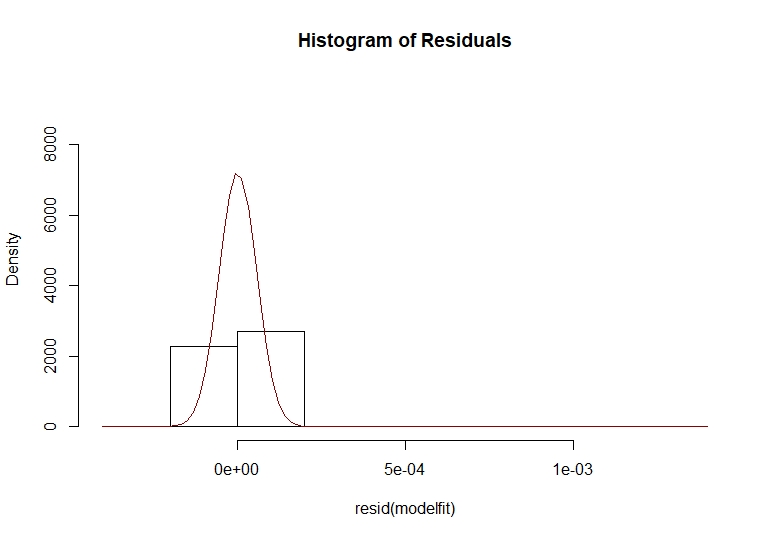
همانطور که می بینیم ، طرح باقیمانده دارای یک تنظیم منحنی طبیعی نزولی است و نکته خوبی برای ادامه این مطالعه به ما می دهد. اکنون می توانیم آخرین طرح باقیمانده خود را بسازیم و باقیمانده های استاندارد شده ، ACF باقیمانده و مقادیر P را برای توطئه های آماری Ljung-Box به ما ارائه دهیم.
# تست های تشخیصی برای Arima tsdiag (modelfit) 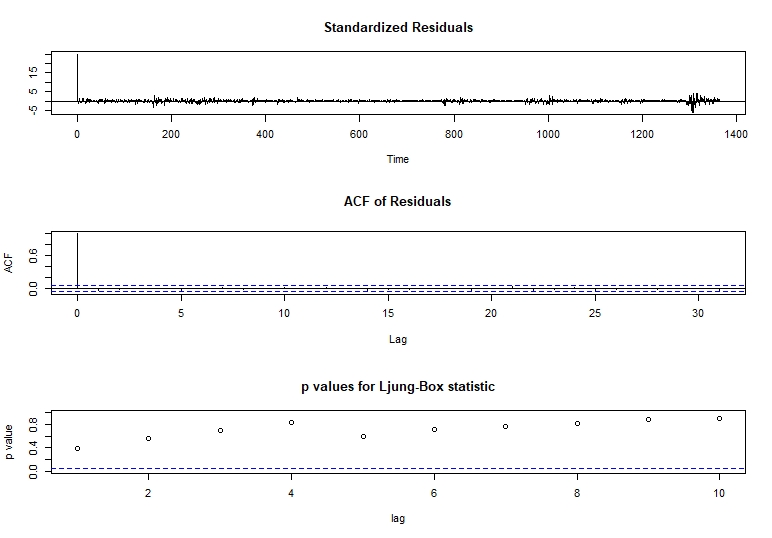
با این 3 نمودار ، ما روی مقادیر p باکس Ljung تمرکز می کنیم. برای آزمون Ljung-Box ما فرضیه تهی ما این است:
Hθ: امتیازات داده به طور مستقل توزیع می شود.
با این فرضیه تهی ، یک مقدار p قابل توجه بیشتر از 0. 05 این واقعیت را رد نمی کند که نقاط مجموعه داده با هم ارتباط ندارند.
در طرح قبلی p-plob-box ، می توانیم ببینیم که در تاخیر 1 مقدار p کوچکتر داریم. با توجه به این بازرسی بصری ، ما به تجزیه و تحلیل این تاخیر با یک آزمایش مستقل می پردازیم.
# تست جعبه برای LAG = 2 Box. Test (Modelfit $ باقیمانده ، LAG = 2 ، TYPE = "Ljung-Box") # تست باکس-لژونگ # داده ها: Modelfit $ باقیمانده # x-squared = 1. 1885 ، df = 2 ، p-value = 0. 552 همانطور که می توانیم ببینیم مقدار p ما هنوز فرضیه تهی ما را رد نمی کند و به ما امکان می دهد یک آزمایش جعبه کلی انجام دهیم.
Box. Test (Modelfit $ باقیمانده ، نوع = "Ljung-Box") # تست جعبه- ljung # داده ها: modelfit $ باقیمانده # x-squared = 0. 76978 ، df = 1 ، p-value = 0. 3803 در این آزمایش عمومی می توانیم ببینیم که فرضیه تهی ما هنوز رد نشده است و به ما امکان می دهد تا با یک انگیزه محکم ، مطالعه خود را ادامه دهیم.
با استفاده از مدل جدید ARIMA ما ، می توانیم پیش بینی مدل را در یک خط قرمز بر روی قیمت قطار واقعی قیمت نزدیک قیمت قرار دهیم.
طرح (as. ts (gspc $ gspc. close)))) (modelfit $ fitted ، col = "red") 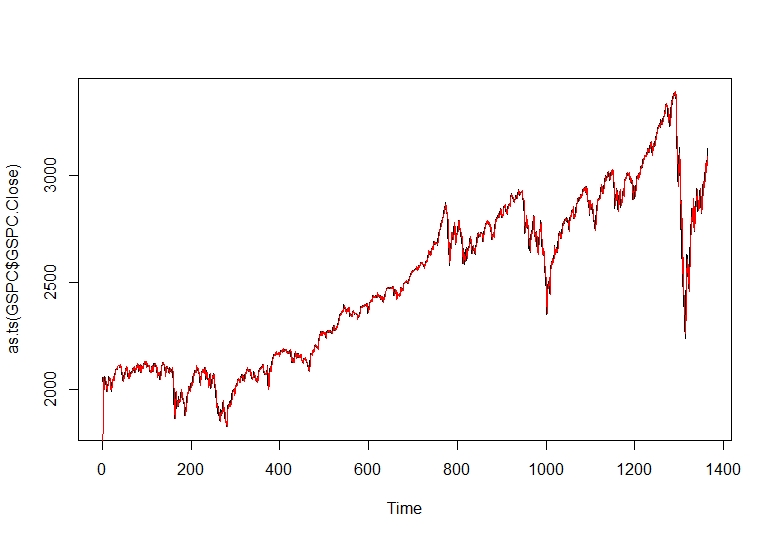
نتایج آریما
اکنون با مدل مناسب می توانیم مقادیر نزدیک قیمت روزانه خود را به آینده پیش بینی کنیم. ما بر پیش بینی قیمت سهام نزدیک برای 30 روز آینده یا یک ماه متوسط تمرکز می کنیم.
اکنون می توانیم پیش بینی خود را برای 30 روز آینده ترسیم کنیم.
طرح (پیش بینی (modelfit ، h = 30)) 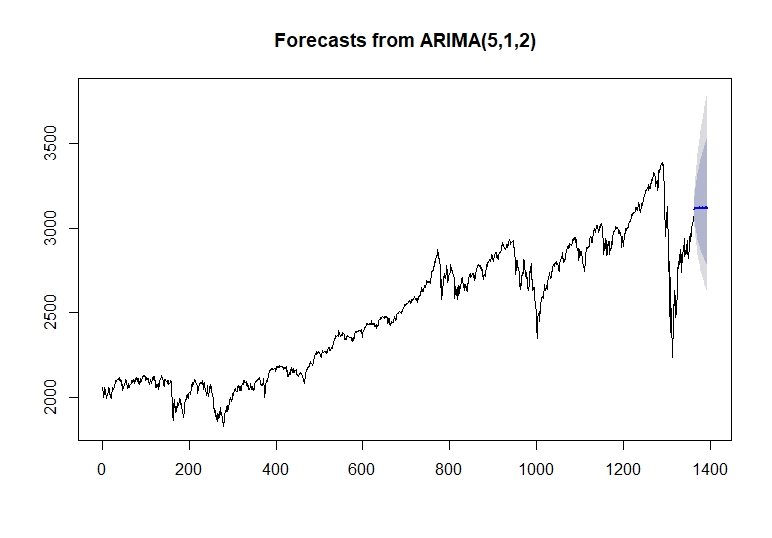
همانطور که می بینیم ، ما یک خط آبی داریم که میانگین پیش بینی ما را نشان می دهد.
Price_forecast# سری زمانی: # شروع = 1365 # پایان = 1370 # فرکانس = 1 # [1] 3113. 484 3120. 944 3119. 524 3118. 773 3122. 801 3116. 676 با توضیح خط آبی ، می توانیم نواحی تیره تر و تاریک تر را ببینیم ، که به ترتیب 80 ٪ و 95 ٪ اطمینان در سناریوهای پایین و فوقانی را نشان می دهد.
سناریوی پایین ما:
# سری زمانی: # شروع = 1365 # پایان = 1370 # فرکانس = 1 # 80 ٪ 95 ٪ # 1365 3043. 480 3007. 509 # 1366 3028. 100 2980. 854 # 1367 3006. 451 2949. 411 # 1368 2987. 954 2954 2922. 422. 467 . 716 2877. 652 سناریوی فوقانی ما:
# سری زمانی: # start = 1365 # پایان = 1370 # فرکانس = 1 # 80 ٪ 95 ٪ # 1365 3186. 300 3226. 041 # 1366 3218. 789 3272. 741 # 1367 3240. 106 3307. 223 # 1368 3259. 759. 759. 759. 888333888. 292. 106 3391. 974 برای به دست آوردن کد دو نتیجه فوق از اینجا بازدید کنید.
نهایی کردن مدل ARIMA ما یک تست سریع و رویکرد مجموعه قطار را با تقسیم داده های قیمت نزدیک انجام می دهیم. ما مجموعه قطار خود را به عنوان 70 درصد از مجموعه داده های خود انتخاب می کنیم. این آزمون 30 درصد باقی مانده از مجموعه داده را تنظیم می کند.
# تقسیم داده ها به مجموعه های قطار و آزمون ، با استفاده از مدل n = طول (gspc $ gspc. close) n = 0. 8*n قطار = gspc $ gspc. close [1: n ،] test = gspc $ gspc. close [((()n+1): n ،] trainarimafitهنگامی که پیش بینی خود را بر روی مجموعه قطار اعمال کردیم ، میانگین تمایل پیش بینی خود را نسبت به مجموعه آزمایش نزدیک قیمت قرار می دهیم.
#Plotting میانگین مقادیر پیش بینی شده در مقابل میانگین داده های واقعی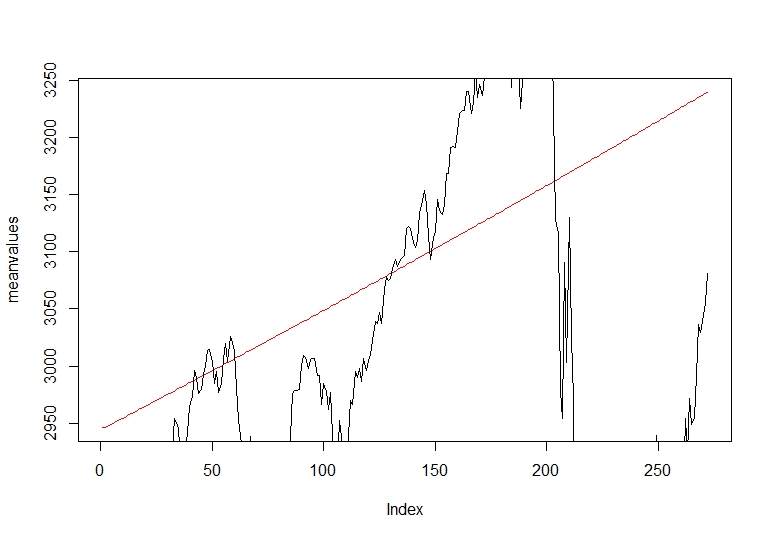
در خط قرمز ما میانگین تمایل پیش بینی پیش بینی خود را نسبت به قیمت نزدیک واقعی سهام می بینیم. گرایش یک رویکرد خوب را نشان می دهد که جهت آینده قیمت نزدیک را پیش بینی می کند.
GARCH: ناهمگونی مشروط به خودی تعمیم یافته
GARCH: ناهمگونی مشروط به خودی تعمیم یافتهمعرفی
معرفیمدل ARIMA قبلی ارائه شده نتایج بسیار خوبی دارد ، اما همانطور که انتظار داشتیم رضایت بخش نیست. این تعصب نتایج اصلی توسط مشاهدات بی ثبات مجموعه مجموعه داده های ما و بازار مالی ما توضیح داده شده است. این وضعیت هنگام پیش بینی ارزش های جدید باعث نگرانی می شود. مدل ناهمگونی مشروط مشروط به خودی ، پایه و اساس ساخت "خوشه بندی نوسانات" را دارد. این خوشه بندی نوسانات بر اساس دوره هایی با حرکات آرام و آرامش نسبی و دوره های نوسانات بالا وجود دارد. این رفتار در داده های بازار سهام مالی بسیار معمولی است همانطور که گفتیم و مدل GARCH یک رویکرد بسیار مناسب برای به حداقل رساندن اثر نوسانات است. از ارزیابی اجرای مدل های GARCH ما باقیمانده های معمولی را می گیریم و سپس آنها را مربع می کنیم. با انجام این توطئه های باقیمانده ، هر مقادیر فرار بصری ظاهر می شود. ما سعی می کنیم یک مدل استاندارد Garch (1 ، 1) را بر روی ARMA (5،2) اعمال کنیم ، و به دنبال این هستیم که آیا دقت و پارامترهای مدل خود را بهبود بخشیده ایم.
ناهمگونی مشروط خودجوش
ناهمگونی مشروط خودجوشمدل ناهمگونی شرطی مشروط (ARCH) یک مدل آماری برای داده های سری زمانی است که واریانس اصطلاح خطای فعلی یا نوآوری را به عنوان تابعی از اندازه واقعی شرایط خطای دوره زمانی قبل توصیف می کند ، اغلب واریانس مربوط به مربع ها است. از نوآوری های قبلیمدل قوس مناسب است که واریانس خطا در یک سری زمانی از یک مدل خودکار (AR) پیروی کند. اگر یک مدل میانگین متحرک (ARMA) برای واریانس خطا فرض شود ، این مدل یک مدل ناهمگونی مشروط مشروط (GARCH) است.
برای مدل سازی یک سری زمانی با استفاده از یک فرآیند قوس ، اجازه دهید Etاصطلاحات خطا را مشخص کنید (باقیمانده های برگشتی ، با توجه به یک فرآیند میانگین) ، یعنی اصطلاحات سری. اینهاtبه یک قطعه تصادفی Z تقسیم می شوندtو یک انحراف استاندارد وابسته به زمان σtتوصیف اندازه معمولی اصطلاحات به طوری
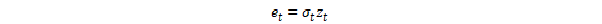
متغیر تصادفی Ztیک فرآیند قوی سر و صدای سفید است. سریال σt^2 توسط مدل سازی شده است ،
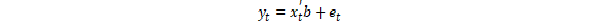
اگر یک مدل ARMA برای واریانس خطا فرض شود ، این مدل یک مدل ناهمگونی مشروط مشروط (GARCH) است. در این حالت ، مدل GARCH (P ، Q) (که در آن P ترتیب GARCH اصطلاحات σ^2 و Q ترتیب اصطلاحات قوس E^2 است) ، به دنبال نماد مقاله اصلی ، توسط
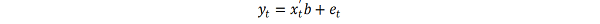
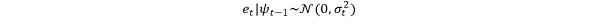
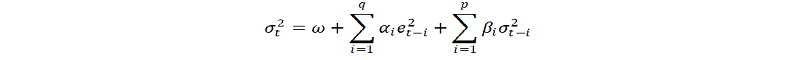
به طور کلی ، هنگام آزمایش برای ناهمگونی در مدلهای اقتصاد سنجی ، بهترین آزمایش آزمایش سفید است. با این حال ، هنگام برخورد با داده های سری زمانی ، این به معنای آزمایش خطاهای Arch و Garch است.
میانگین متحرک یکپارچه یکپارچه خودکار
میانگین متحرک یکپارچه یکپارچه خودکارمدلهای متوسط متحرک یکپارچه خود به طور کامل یکپارچه مدل های سری زمانی هستند که مدل های ARIMA (میانگین متحرک یکپارچه خود را) با اجازه دادن به مقادیر غیر اینتگر پارامتر متفاوت ، تعمیم می دهند. این مدلها در مدل سازی سری زمانی با حافظه طولانی مفید هستند-یعنی ، که در آن انحراف از میانگین پوسیدگی طولانی تر از یک پوسیدگی نمایی است. مخفف مخفف Arfima یا Farima اغلب مورد استفاده قرار می گیرد ، اگرچه معمولی است که به سادگی نمادهای ARIMA (P ، D ، Q) را برای مدل ها گسترش دهیم ، با اجازه دادن به ترتیب متفاوت ، D ، مقادیر کسری را بدست آورند. یک مدل آرفیما همان شکل بازنمایی را با فرآیند Arima (P ، D ، Q) به اشتراک می گذارد ، به طور خاص
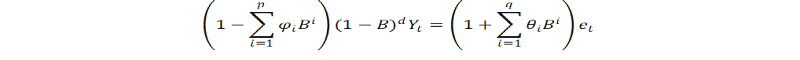
بر خلاف فرآیند معمولی ARIMA ، "پارامتر اختلاف" ، D ، مجاز به گرفتن مقادیر غیر ایندره است.
ما برای یافتن پارامترهای ARFIMA (میانگین متحرک یکپارچه یکپارچه) که قبلاً در مجموعه داده های نزدیک به قیمت تعریف شده است ، استفاده می کنیم.
# مناسب Afrima fitarfima = autoarfima (data = gspc $ gspc. close ، ar. max = 5 ، ma. max = 2 ، criterion = "aic" ، method = "full") fitarfima $ fit *----------------------------------* * ARFIMA Model Fit * *----------------------------------* Mean Model : ARFIMA(5,0,2) Distribution : norm Optimal Parameters Estimate Std.Error t value Pr(>|t|) mu 2015.42371 4.438054 454.1233 0.000000 ar1 -0.69994 0.053413 -13.1044 0.000000 ar2 0.97147 0.039540 24.5692 0.000000 ar3 0.91525 0.063107 14.5031 0.000000 ar4 -0.12205 0.035448 -3.4431 0.000575 ar5 -0.09518 0.039793 -2.3919 0.016763 ma1 1.62233 0.043906 36.9498 0.000000 ma2 0.72284 0.034990 20.6587 0.000000 sigma 28.69536 0.577512 49.6879 0.000000 Robust Standard Errors: Estimate Std.Error t value Pr(>| T |) MU 2015. 42371 5. 845048 344. 80877 0. 000000 AR 1-0. 69994 0. 15093 1-4. 63750 0. 000004 AR2 0. 977737 16. 82585 0. 000000 AR3 0. 91525 0. 1855642 2. 42537 0. 015293 AR 5-0. 09518 0. 10459 3-0. 91001 0. 362818 MA1 1. 62233 0. 079718 20. 35094 0. 000000 MA2 0. 72284 0. 034451 20. 9818181 0. 00000000000000SIGMA 28. 69536 4. 091210 7. 01391 0. 000000 ورود به سیستم: -6514. 02 معیارهای اطلاعاتی با نام مستعار 9. 5645 Bayes 9. 5990 Shibata 9. 5645 Hannan-Quinn 9. 5774 وزنه بردار Ljung-Box در آزمون STANDADISISTIONISIAD P+q)+(p+q) -1] [20] 38. 217 0. 00e+00 LAG [4*(p+q)+(p+q) -1] [34] 55. 897 2. 22e-16 H0: بدون همبستگی سریالتست وزنی Ljung-Box در باقیمانده های استاندارد Squared Statistic P-Value Lag [1] 354. 3 0 LAG [2*(P+Q)+(P+Q) -1] [2] 530. 5 0 LAG [4*(P+Q)+(P+q) -1] [5] 921. 4 0 Arch LM آزمون آماری DOF P-Value Arch Lag [2] 466. 6 2 0 Arch Lag [5] 509. 7 5 0 Arch Lag [10] 562. 5 10 0 Nyblom Test Pataitionآمار مشترک: 11. 832 آمار فردی: MU 0. 09505 AR1 2. 08097 AR2 2. 15325 AR3 1. 50304 AR4 2. 67606 AR5 2. 26071 MA1 0. 02611 MA2 0. 08301 SIGMA 7. 01724 مقادیر بحرانی 0. 30: 2. 32 statistic. با پارامترهای جمع آوری شده Arfima (3،0،2) را انتخاب می کنیم و پارامترها را در یک مدل GARCH گنجانیم.
# مدل GARCH11CLOSEPRICE = UGARCHSPEC (واریانس. model = لیست (garchorder = c (1،1)) ، میانگین. model = لیست (armaorder = c (3،2))) # تخمین مدل garch11closepricefit = ugarchfit (Spec = garch11closeprice، data = gspc $ gspc. close) با داشتن مدل خود ، می توانیم یک طرح نوسانات ایجاد کنیم.
# طرح نوسانات مشروط طرح توطئه. 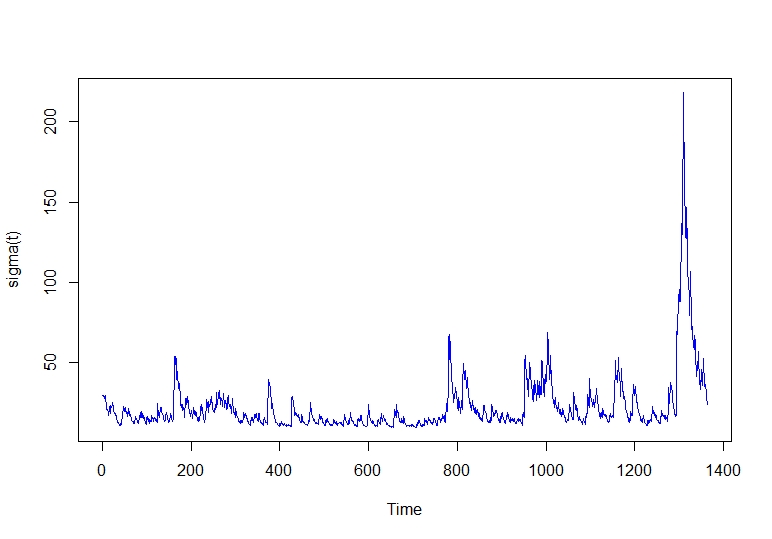
همانطور که می بینیم ، سالهای آخر داده های ما قله های بالاتری دارند که با بی ثباتی اقتصادی در بازارها در سالهای گذشته توضیح داده شده است. ما می توانیم Akaike و سایر اطلاعات مدل خود را ببینیم.
# Infocriteria # مدل Akike (Garch11closePriceFit) # Model Akaike # Akaike 8. 768009 # Bayes 8. 802440 # Shibata 8. 767923 # Hannan-Quinn 8. 780897 # باقیمانده های طبیعی Garchres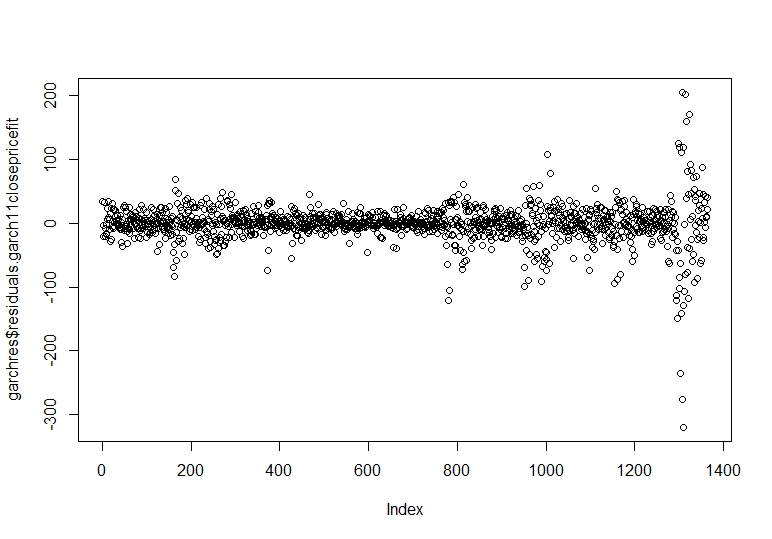
اکنون ما به محاسبه و ترسیم باقیمانده های استاندارد می پردازیم.
# گارچ های باقیمانده استاندارد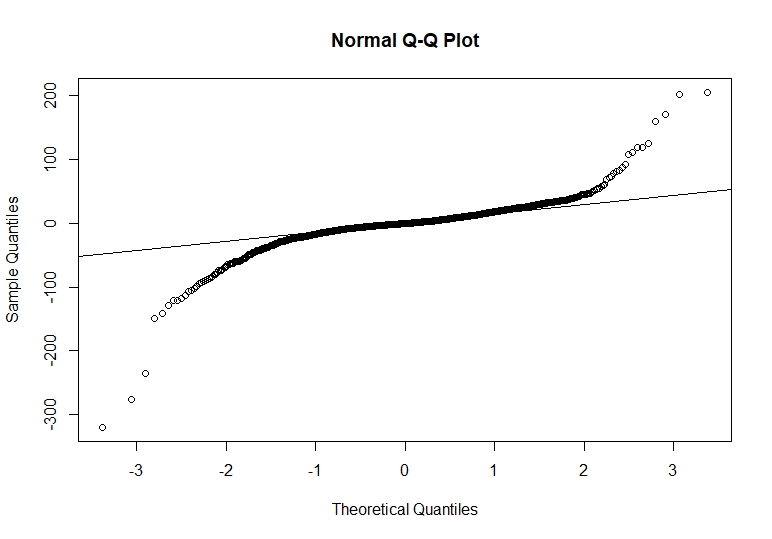
ما می بینیم که مقادیر افراطی داریم که خارج از توزیع عادی هستند ، اما اکثر نقاط داده در خط محور هستند. با داشتن طرح نرمال بودن باقیمانده های استاندارد ما ، یک تست جعبه Ljung را به باقیمانده های استاندارد مربع تبدیل می کنیم.
#باقیمانده استاندارد Squared Ljung Box Garchres# جعبه لیونگ باقیمانده استاندارد Squared # تست جعبه-لژونگ # x-squared = 1. 289 ، df = 1 ، p-value = 0. 2562 با آزمایش جعبه Ljung می بینیم که باقیمانده های مربع استاندارد ما فرضیه تهی را رد نمی کنند و تأیید می کنیم که ما بین آنها همبستگی نداریم. از آنجا که ما نوسانات و رفتار باقیمانده خود را پیدا کردیم می توانیم 30 روز آینده خود را پیش بینی کنیم و با سایر مدل ها مقایسه کنیم.
پیش بینی گارچ
پیش بینی گارچبا مدل متناسب و مقادیر پیش بینی شده پیش بینی داده های خود را ترسیم می کنیم.
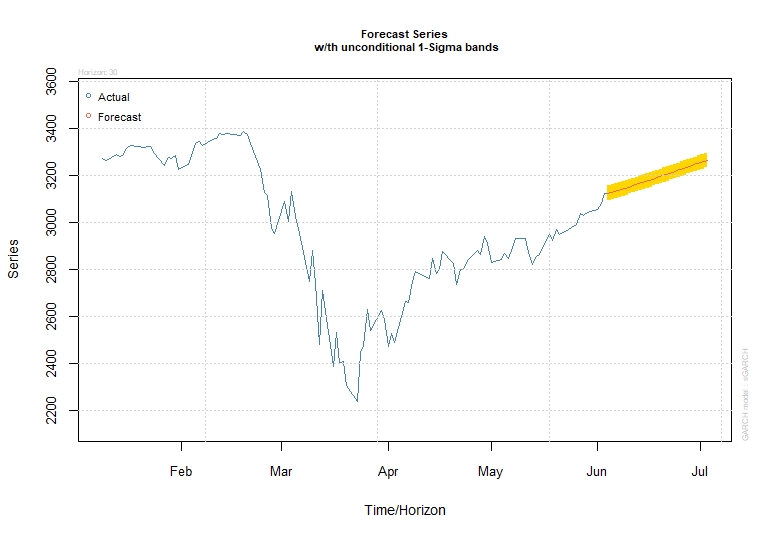
همانطور که ما از Garch برای تصحیح پیش بینی های ARIMA خود استفاده می کنیم ، این مدل را عمیقاً ارزیابی نمی کنیم.
برای دریافت کد نمودار فوق از اینجا بازدید کنید.
نبی - پیامبر
نبی - پیامبرمنشأ پیامبر ناشی از استفاده از یک مدل پیش بینی در مدیریت زنجیره تأمین ، فروش و اقتصاد است. این مدل به یک رویکرد آماری در شکل گیری تصمیمات تجاری کمک می کند. مدل پیامبر توسط تیم اصلی علوم داده فیس بوک ساخته شده است و این یک ابزار منبع باز برای پیش بینی تجارت است.
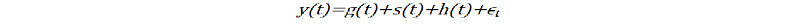
مدل پیامبر یک مدل افزودنی با مؤلفه های G (T) مدل ها ، مدل های S (T) فصلی با سری فوریه ، H (T) اثرات تعطیلات یا وقایع بزرگ است. برای این مطالعه ، ما نمی خواهیم عملکردهای مدل پیامبر را عمیقاً مورد تجزیه و تحلیل قرار دهیم زیرا آنها خیلی متراکم و عمیق هستند که به یک مطالعه مستقل جدید نیاز دارد اما ما توضیحاتی را انجام دادیم.
پیش بینی پیامبر
پیش بینی پیامبرپیش بینی #PROPHET #بارگیری سری زمانی پیش بینی بسته پیامبر ## ایجاد DataFrame و برنامه Model DF#CREATING DATASET پیش بینی قطار برای مقایسه داده های واقعی داده ها = داده ها. 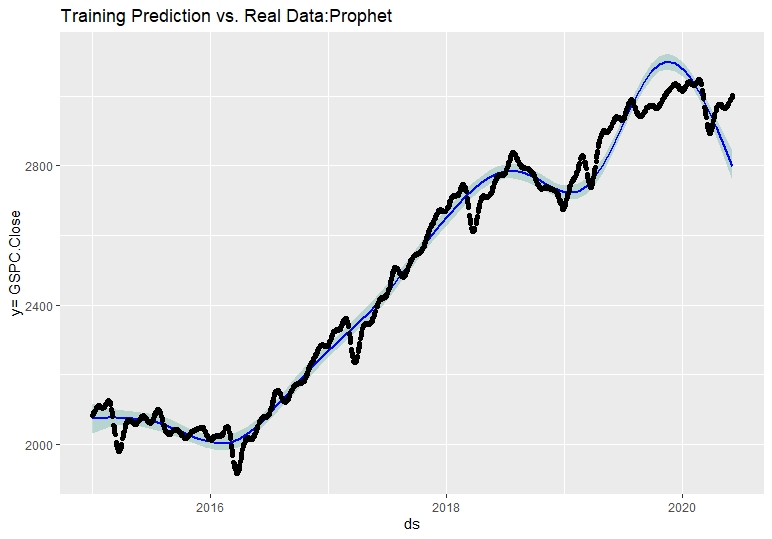
برای دریافت کد نمودار فوق از اینجا بازدید کنید.
با استفاده از مدل اعمال شده و پیش بینی ترسیم شده ، ما به محاسبه عملکرد مدل می پردازیم. از آنجا که ما در این برنامه مدل جدید هستیم ، از عملکرد دقت برای مقایسه مقادیر واقعی در برابر مقادیر برآورد شده مجموعه قطار استفاده خواهیم کرد. رویکرد صحیح برای انجام این کار در پیامبر ایجاد یک فرآیند اعتبارسنجی متقابل و تجزیه و تحلیل معیارهای عملکرد مدل است ، اما ما در تلاش هستیم تا Arima در مقابل سایر مدل ها را با همان رویکرد مقایسه کنیم.
هنگامی که ما مجموعه داده خود را برای مقایسه داده های واقعی در برابر مقادیر پیش بینی شده ایجاد کردیم ، ما به محاسبه دقت ادامه می دهیم.
#دقت اعتبار سنجی متقابل (DataPrediction $ fcastprophet. yhat ، df $ y) # me rmse mae mpe mape # مجموعه آزمایش 0. 01260116 96. 05275 64. 8858 1-0. 1404824 2. 58817 در نهایت برای درک بهتر مجموعه داده ها، می توانیم مؤلفه های پیامبر خود را تقسیم بر مولفه روند، فصلی هفتگی و فصلی سالانه ترسیم کنیم.
prophet_plot_components(prophet_pred, fcastprophet) 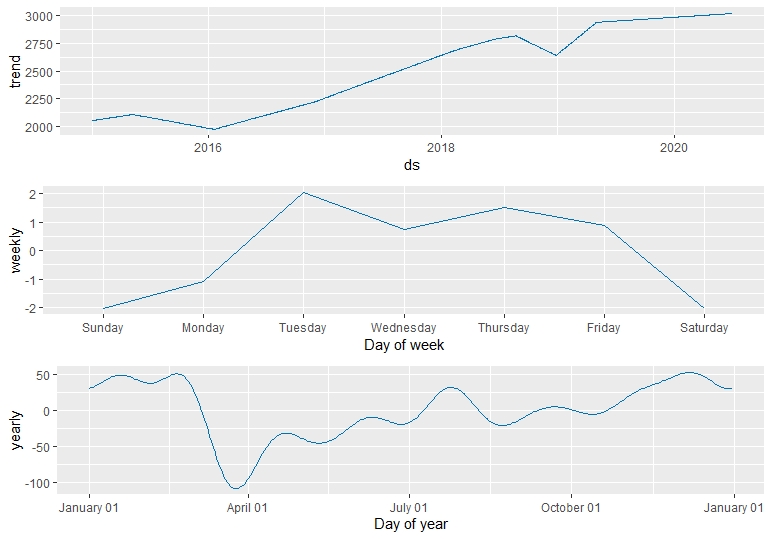
رگرسیون KNN برای پیش بینی سری های زمانی
رگرسیون KNN برای پیش بینی سری های زمانی
مدل KNN را می توان برای مسائل طبقه بندی و رگرسیون استفاده کرد. محبوب ترین برنامه استفاده از آن برای مشکلات طبقه بندی است. در حال حاضر، KNN همچنین می تواند برای هر کار رگرسیونی پیاده سازی شود. ایده این مطالعه نشان دادن ابزارهای مختلف پیش بینی، مقایسه آنها و تحلیل رفتار پیش بینی ها است. به دنبال مطالعه KNN ما، پیشنهاد کردیم که می توان از آن برای مشکلات طبقه بندی و رگرسیون استفاده کرد. برای پیش بینی مقادیر نقاط داده جدید، مدل از «شباهت ویژگی» استفاده می کند، و یک نقطه جدید را به مقادیر بر اساس شباهت آن به نقاط مجموعه آموزشی اختصاص می دهد. هدف اصلی ما تلاش برای پیش بینی مقادیر جدید قیمت سهام با استفاده از آن است. یک رویکرد تجربی KNN
برای این پیش بینی، ما از یک k برابر با 50 به عنوان یک مقدار آزمایشی استفاده می کنیم، زیرا یک رویکرد اکتشافی در تلاش برای یافتن بهترین مقدار k انجام دادیم. الگوریتم های KNN به آزمایش های تنظیم نیاز دارند، اما از آنجایی که این مطالعه برای نشان دادن ابزارهای مختلف پیش بینی است، ما به جای تنظیم مدل برای به دست آوردن بهترین دقت، عمیقاً روی کاربرد برنامه ریزی خواهیم کرد.
#Dataframe ایجاد و مدل اپلیکیشن dfدقت مدل مجموعه #قطار ro# RMSE MAE MAPE # 153. 8021 131. 9580 4. 7621 با استفاده از تابع مبدا نورد، از مدل و سری های زمانی مرتبط برای ارزیابی دقت پیش بینی مدل استفاده می کنیم. هنگامی که مدل خود را مطالعه کردیم، می توانیم پیش بینی های خود را در نمودار زیر رسم کنیم.
طرح خودکار (predknn) 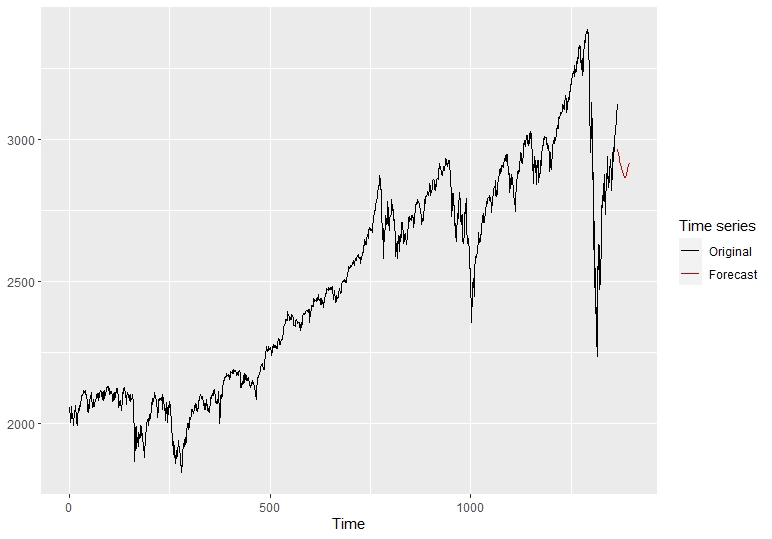
با داشتن این نمودار جدید پیش بینی KNN، اکنون می توانیم آن را با مدل های دیگر مقایسه کنیم. قبل از مقایسه پیش بینی ها، ما بر روی مدل چهارم و آخرین رویکرد اعمال شده برای پیش بینی با شبکه های عصبی تمرکز خواهیم کرد.
شبکه های عصبی پیشخور
شبکه های عصبی پیشخورشبکه عصبی تک لایه پنهان ساده ترین شکل شبکه عصبی است. در این فرم لایه پنهان تنها یک لایه از گره های ورودی وجود دارد که ورودی های وزنی را به لایه بعدی گره های دریافت کننده ارسال می کند. ما یک مدل شبکه عصبی تک لایه پنهان را به یک سری زمانی برازش می دهیم. رویکرد مدل تابعی استفاده از مقادیر تاخیری سری های زمانی به عنوان داده های ورودی است که به یک مدل خودرگرسیون غیر خطی می رسد.
برای این رویکرد ، تعداد مشخصی از گره های پنهان نیمی از تعداد گره های ورودی (از جمله رأی دهندگان خارجی ، در صورت داده شده) به علاوه 1. ما از یک جعبه cox lambda استفاده می کنیم تا اطمینان حاصل شود که باقیمانده ها تقریباً همجنسگرا هستند. ما 30 مقدار بعدی را با خالص عصبی متناسب پیش بینی می کنیم.
#fitting nnetar lambda = boxcox. lambda (gspc $ gspc. close) dnn_fit = nnetar (gspc [، 4] ، lambda = lambda) dnn_fit در زیر خلاصه مدل از مدل شبکه های عصبی Feed Forward است.
# سری: GSPC [، 4] # مدل: NNAR (11،6) # تماس: nnetar (y = gspc [، 4] ، lambda = lambda) # میانگین 20 شبکه که هر یک از آنها # 11-6 است1 شبکه با 79 وزن # گزینه ها - واحدهای خروجی خطی # سیگما^2 تخمین زده می شود 1. 187 E-09 fcast = پیش بینی (dnn_fit ، pi = t ، h = 30) autoplot (fcast) 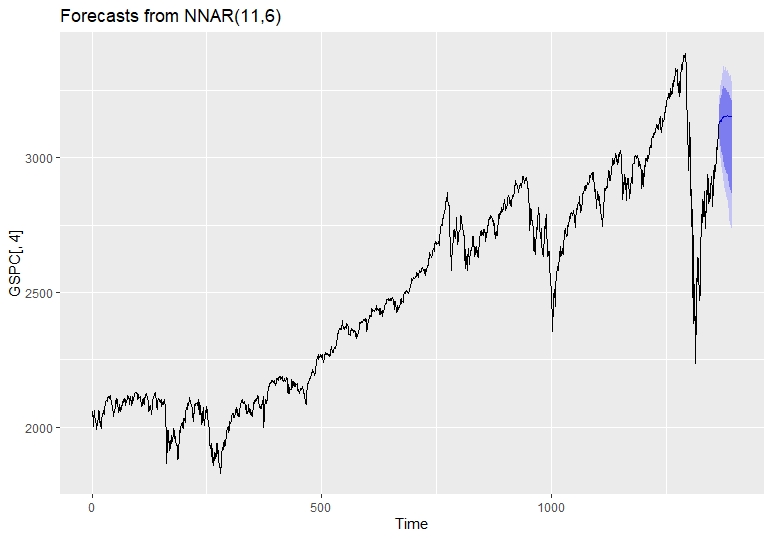
دقت (DNN_FIT) # me rmse mae mpe mape mase acf1 # 0. 2082332 22. 74244 15. 2940 5-0. 001138679 0. 6109943 0. 8848755 0. 03257684 نتیجه
نتیجهدر این مطالعه ما در استفاده از مدلهای مختلف متمرکز شده ایم و یاد می گیریم که چگونه از آنها با هدف پیش بینی مقادیر قیمت جدید استفاده کنیم. همانطور که از نتایج خود می بینیم ، مدل های انجام شده با پیش بینی های تمایل مشابه آینده. تمام مدل ها تمایل به قیمت بالاتر در 30 روزهای بعدی را پیش بینی کردند. ما می توانیم نتیجه بگیریم که مدل های ARIMA و NEURAL NEUR در فواصل پیش بینی و معیارهای دقت بسیار خوب عمل می کنند. مدل های دیگر به عنوان جدید در این رویکرد پیش بینی جدید هستند و هدف این است که آنها را به صورت بصری انجام دهیم و همچنین مدل های ARIMA یا NEURAL NEUR انجام نشود. شاید پیامبر و KNN برای به دست آوردن نتایج دقیق تر به تنظیم بیشتری نیاز داشته باشند. نکته بسیار مرتبط با ما که ذکر نکرده ایم این است که مدل های رگرسیون خودکار ، زیرا آنها بر روی داده های گذشته برای پیش بینی مقادیر آینده پایه گذاری می شوند ، تمایل دارند پیش بینی های بدون علامت در پیش بینی های آینده طولانی داشته باشند. سرانجام ، نتیجه می گیریم که آریما و شبکه های عصبی بهترین مدل های پیش بینی کننده در این سناریو هستند ، در حالی که گارچ را با رویکرد ARIMA ما درج می کنیم ، نتایج بسیار جالبی داشتیم. مدل های دیگر مورد استفاده و همچنین ARIMA و NET های عصبی تحت معیارهای ما انجام نشده است ، اما این می تواند به این دلیل باشد که ممکن است به مراحل تنظیم و آموزش بیشتری ، رویکردهای آزمایش نیاز داشته باشند یا به دلیل استفاده اصلی از سایر مدل ها به اندازه سایر مدل ها مؤثر نیستنداصطلاحات طبقه بندی بیش از پیش بینی.
ارجاع
ارجاعاینها منابع ارزشمندی برای این پروژه بودند.
A. Trapletti و K. Hoik (2016). tseries: تجزیه و تحلیل سری زمانی و امور مالی محاسباتی. نسخه بسته R 0. 10-35.

ما را در سایت نرم افزار مفید تریدر دنبال می کنید
برچسب :
نویسنده : احمد شاملو
بازدید : 28
