- تله سرمایه گذار: از خفه کردن و سوزاندن مراقب باشید
- 7 راه برای استفاده از هوش مصنوعی اکنون برای تأثیرگذاری بر مدیریت ریسک و جلوگیری از غرق شدن در داده ها
- مبادلات ، سوپر های الکترونیکی و بازپرداخت
- الگوریتم های معاملاتی هوشمند
- گزینه های سرمایه گذاری
- ثروتمندترین معامله گران فارکس
- 4 دلیل شما باید Dogecoin را بفروشید و چرا ممکن است آن را حفظ کنید
- سرمایه گذاری در مایع هوایی
- بحران ارز
- سهام جویدنی به عنوان درآمد نشان می دهد که تعداد مشتری را کاهش می دهد ، پیش بینی رشد سود

آخرین مطالب
امکانات وب




ضریب همبستگی ، R ، در مورد قدرت رابطه خطی بین x و y به ما می گوید. با این حال ، قابلیت اطمینان مدل خطی نیز بستگی به تعداد نقاط داده مشاهده شده در نمونه دارد. ما باید به هر دو مقدار ضریب همبستگی R و اندازه نمونه N ، با هم نگاه کنیم.
ما یک آزمون فرضیه از "اهمیت ضریب همبستگی" را انجام می دهیم تا تصمیم بگیریم که آیا رابطه خطی در داده های نمونه به اندازه کافی قوی است که می تواند برای مدل سازی رابطه در جمعیت استفاده کند.
از داده های نمونه برای رایانه r ، ضریب همبستگی برای نمونه استفاده می شود. اگر برای کل جمعیت داده داشتیم ، می توانستیم ضریب همبستگی جمعیت را پیدا کنیم. اما از آنجا که ما فقط داده های نمونه داریم ، نمی توانیم ضریب همبستگی جمعیت را محاسبه کنیم. ضریب همبستگی نمونه ، R ، برآورد ما از ضریب همبستگی جمعیت ناشناخته است.
نماد ضریب همبستگی جمعیت ρ ، حرف یونانی "Rho" است.
ρ = ضریب همبستگی جمعیت (ناشناخته)
R = ضریب همبستگی نمونه (شناخته شده ؛ از داده های نمونه محاسبه شده است)
آزمون فرضیه به ما امکان می دهد تصمیم بگیریم که آیا ارزش ضریب همبستگی جمعیت "نزدیک به 0" است یا "به طور قابل توجهی با 0" متفاوت است. ما این را بر اساس ضریب همبستگی نمونه R و اندازه نمونه n تصمیم می گیریم.
اگر آزمون نتیجه بگیرد که ضریب همبستگی با 0 تفاوت معنی داری دارد ، ما می گوییم که ضریب همبستگی "قابل توجه" است.
- نتیجه گیری: "شواهد کافی وجود دارد که نتیجه بگیریم که رابطه خطی قابل توجهی بین x و y وجود دارد زیرا ضریب همبستگی تفاوت معنی داری با 0 دارد."
- نتیجه گیری به این معنی است: رابطه خطی قابل توجهی بین x و y وجود دارد. ما می توانیم از خط رگرسیون برای الگوبرداری از رابطه خطی بین x و y در جمعیت استفاده کنیم.
اگر آزمون نتیجه بگیرد که ضریب همبستگی تفاوت معنی داری با 0 ندارد (نزدیک به 0 است) ، ما می گوییم که ضریب همبستگی "قابل توجه" نیست.
- نتیجه گیری: "شواهد کافی وجود ندارد که نتیجه بگیریم که رابطه خطی قابل توجهی بین x و y وجود دارد زیرا ضریب همبستگی تفاوت معنی داری با 0 ندارد."
- نتیجه گیری به این معنی است: بین x و y رابطه خطی قابل توجهی وجود ندارد. بنابراین ما نمی توانیم از خط رگرسیون برای الگوبرداری از رابطه خطی بین x و y در جمعیت استفاده کنیم.
- اگر R قابل توجه باشد و طرح پراکندگی روند خطی را نشان می دهد ، می توان از این خط برای پیش بینی مقدار y برای مقادیر X که در دامنه مقادیر X مشاهده شده است استفاده کرد.
- اگر R قابل توجه نباشد یا اگر طرح پراکندگی روند خطی را نشان ندهد ، نباید از خط برای پیش بینی استفاده شود.
- اگر R قابل توجه باشد و اگر طرح پراکندگی روند خطی را نشان دهد ، ممکن است خط برای پیش بینی خارج از دامنه مقادیر X مشاهده شده در داده ها مناسب یا قابل اعتماد نباشد.
انجام آزمون فرضیه تنظیم فرضیه ها:
این فرضیه ها در کلمات چیست:
- فرضیه تهی hای: ضریب همبستگی جمعیت تفاوت معنی داری با 0 ندارد. رابطه خطی معنی داری (همبستگی) بین x و y در جمعیت وجود ندارد.
- فرضیه جایگزین H A: ضریب همبستگی جمعیت با 0 تفاوت معنی داری دارد. یک رابطه خطی معنی داری (همبستگی) بین x و y در جمعیت وجود دارد.
نتیجه گیری:
دو روش برای تصمیم گیری وجود دارد. هر دو روش معادل هستند و نتیجه یکسان را می دهند.
روش 1: با استفاده از مقدار p
روش 2: با استفاده از یک جدول از مقادیر بحرانی
در این فصل از این کتاب درسی ، ما همیشه از سطح معنی داری 5 ٪ ، α = 0. 05 استفاده خواهیم کرد
توجه: با استفاده از روش p-value ، می توانید هر سطح اهمیت مناسب مورد نظر خود را انتخاب کنید. شما محدود به استفاده از α = 0. 05 نیستید. اما جدول مقادیر بحرانی ارائه شده در این کتاب درسی فرض می کند که ما از سطح معنی داری 5 ٪ ، α = 0. 05 استفاده می کنیم.(اگر می خواستیم از سطح اهمیت متفاوتی از 5 ٪ با روش ارزش بحرانی استفاده کنیم ، به جداول مختلفی از مقادیر بحرانی که در این کتاب درسی ارائه نشده است ، نیاز داریم.)
روش 1: استفاده از مقدار p برای تصمیم گیری
On the LinRegTTEST input screen, on the line prompt for β or ρ , highlight " 0" The output screen shows the p-value on the line that reads "p p">اگر مقدار p کمتر از سطح اهمیت باشد (α = 0. 05):
- تصمیم: فرضیه تهی را رد کنید.
- نتیجه گیری: "شواهد کافی وجود دارد که نتیجه بگیریم که رابطه خطی قابل توجهی بین x و y وجود دارد زیرا ضریب همبستگی تفاوت معنی داری با 0 دارد."
اگر مقدار p از سطح اهمیت کمتر نباشد (α = 0. 05):
- تصمیم: فرضیه تهی را رد نکنید.
- نتیجه گیری: "شواهد کافی وجود ندارد که نتیجه بگیریم که رابطه خطی قابل توجهی بین x و y وجود دارد زیرا ضریب همبستگی تفاوت معنی داری با 0 ندارد."
یادداشت های محاسبه:
شما از فناوری برای محاسبه مقدار p استفاده خواهید کرد. موارد زیر محاسبات را برای محاسبه آمار آزمون و مقدار p شرح می دهد: مقدار P با استفاده از توزیع T با N-2 درجه آزادی محاسبه می شود.
فرمول آمار آزمون است. مقدار آمار آزمون ، t ، در رایانه یا خروجی ماشین حساب به همراه مقدار p نشان داده شده است. آمار آزمون T دارای همان علامت ضریب همبستگی r است.
مقدار p منطقه ترکیبی در هر دو دم است.
یک روش جایگزین برای محاسبه مقدار p (p) داده شده توسط linregttest ، فرمان 2*tcdf (abs (t) ، 10^99 ، n-2) در 2nd dist است.
امتحان سوم در مقابل مثال آزمون نهایی: روش ارزش P
- مثال امتحان سوم/مثال نهایی را در نظر بگیرید.
- خط بهترین تناسب: با R = 0. 6631 و N = 11 نقطه داده وجود دارد.
- آیا می توان از خط رگرسیون برای پیش بینی استفاده کرد؟با توجه به نمره آزمون سوم (مقدار X) ، آیا می توانیم از خط برای پیش بینی نمره امتحان نهایی (مقدار Y پیش بینی شده) استفاده کنیم؟
مقدار p 0. 026 (از linregttest در ماشین حساب شما یا از نرم افزار رایانه ای) مقدار p ، 0. 026 ، کمتر از سطح قابل توجه تصمیم α = 0. 05 است: فرضیه تهی را رد کنیدoنتيجه گيري: شواهدي متضادي وجود دارد كه نتيجه مي شود كه رابطه خطي قابل توجه بين x و y وجود دارد ، زيرا ضریب همبستگي با 0 تفاوت دارد.
از آنجا که R قابل توجه است و طرح پراکندگی روند خطی را نشان می دهد ، می توان از خط رگرسیون برای پیش بینی نمرات امتحان نهایی استفاده کرد.
روش 2: استفاده از جدول مقادیر بحرانی برای تصمیم گیری
مقادیر بحرانی 95 ٪ جدول ضریب همبستگی نمونه در پایان این فصل (قبل از خلاصه) ممکن است مورد استفاده قرار گیرد تا ایده خوبی در مورد اینکه آیا مقدار محاسبه شده R قابل توجه است یا خیر ، استفاده شود. R را با مقدار بحرانی مناسب در جدول مقایسه کنید. اگر R بین مقادیر بحرانی مثبت و منفی نباشد ، ضریب همبستگی معنی دار است. اگر R قابل توجه است ، ممکن است بخواهید از خط برای پیش بینی استفاده کنید.
مثال 6. 7
فرض کنید شما R = 0. 801 را با استفاده از N = 10 Data محاسبه کرده اید. df = n-2 = 1 0-2 = 8. مقادیر بحرانی مرتبط با df = 8-0. 632 و + 0. 632 هستند. اگر r
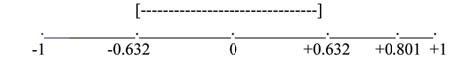
Figure 6.13 r is not significant between -0.632 and +0.632. r = 0.801>+0. 632. بنابراین r قابل توجه است.
مثال 6. 8
فرض کنید r = -0. 624 را با 14 نقطه داده محاسبه کرده اید. df = 14 − 2 = 12. مقادیر بحرانی 0. 532- و 0. 532 هستند. از آنجایی ک ه-0. 624r قابل توجه است و خط ممکن است برای پیش بینی استفاده شود

فرض کنید r = 0. 776 و n = 6 را محاسبه کرده اید. df = 6 − 2= 4. مقادیر بحرانی 0. 811- و 0. 811 هستند. از 0. 811-<0.776 <0.811, r is not significant and the line should not be used for prediction.

THIRD EXAM vs FINAL EXAM EXAMPLE: روش ارزش بحرانی
- نمونه امتحان نهایی امتحان سوم را در نظر بگیرید.
- خط بهترین تناسب این است: با r = 0. 6631 و n = 11 نقطه داده وجود دارد.
- آیا می توان از خط رگرسیون برای پیش بینی استفاده کرد؟با توجه به نمره آزمون سوم (مقدار X) ، آیا می توانیم از خط برای پیش بینی نمره امتحان نهایی (مقدار Y پیش بینی شده) استفاده کنیم؟
از جدول "95% ارزش بحرانی" برای r با df = n − 2 = 11 − 2 = 9 استفاده کنید
مقادیر بحران ی-0. 602 و +0. 602 هستند
Since 0.6631>0. 602، r قابل توجه است.
تصمیم: رد Hای:
نتیجه گیری: شواهد کافی برای نتیجه گیری وجود رابطه خطی معنادار بین x و y وجود دارد، زیرا ضریب همبستگی با 0 تفاوت معناداری دارد.
از آنجا که R قابل توجه است و طرح پراکندگی روند خطی را نشان می دهد ، می توان از خط رگرسیون برای پیش بینی نمرات امتحان نهایی استفاده کرد.
مثال 6. 10: مثال های تمرینی اضافی با استفاده از ارزش های بحرانی
فرض کنید ضرایب همبستگی زیر را محاسبه کرده اید. با استفاده از جدول انتهای فصل، تعیین کنید که آیا r مهم است یا خیر و خط بهترین تناسب مرتبط با هر r می تواند برای پیش بینی مقدار y استفاده شود. اگر کمک کرد، یک خط عددی بکشید.
نرم افزار مفید تریدر...
ما را در سایت نرم افزار مفید تریدر دنبال می کنید
برچسب :
نویسنده : احمد شاملو
بازدید : 55
